Published: 2026-04-08. Data note: leaderboard scores below were cross-checked against arena history on 2026-04-07 UTC. Change descriptions come from the iteration logs and tracked submission notes.
Announcement note: Sentient published the Cohort 0 results on 2026-04-15 in “The results are in: Meet the winners of Cohort 0”, listing RETRO / Robert Amanfu in 5th place.
This was my final report for Treasury Reapers, my team name for Sentient Arena Challenge 0: Grounded Reasoning. The challenge asked participants to build agents for OfficeQA, where the agent answers precise financial questions from the U.S. Treasury Bulletin corpus.
Team info
| Field | Value |
|---|---|
| Team name | Treasury Reapers |
| Team members | Robert Amanfu |
| Challenge | Sentient Arena Challenge 0: Grounded Reasoning |
| Public announcement | 5th place as RETRO / Robert Amanfu in Sentient’s Cohort 0 results, published 2026-04-15 |
| Best leaderboard score | 183.481 |
| Best submission | 21458905 on 2026-04-06 |
| Final stack direction | goose harness + custom OfficeQA prompt + skill contracts |
What was built
The system is a grounded reasoning agent for OfficeQA over the Treasury Bulletin corpus: a custom Jinja2 prompt template plus skill contracts packaged as markdown files:
bulletin-retriever — rules for selecting the right Treasury Bulletin issue, normalizing fiscal-year boundaries, and preferring retrospective tables over month-by-month expansion
plaintext-table-parser — rules for locating table blocks by caption, splitting fixed-width rows, normalizing labels (Jan/Jan./January), and handling parenthetical negatives
arithmetic-verifier — rules for safe summation, percent change, unit conversion, and avoiding double-counting of subtotals
cross-doc-aggregator — rules for merging data across multiple bulletin files, detecting duplicates, and checking period coverage
answer-writer — mandatory answer-file contract: write early, overwrite if improved, verify before stopping
python-computation — rules for writing self-contained
/app/calc.pyscripts using only the standard library
A checklist of known failure modes (answer-file hygiene, arithmetic pitfalls, fiscal-year semantics, retrieval heuristics, output formatting, timeout prevention) was injected into the agent’s context alongside the skills.
An EvoSkill-style iteration loop (propose, distill, analyze) mined agent traces into reusable prompt and skill updates.
A few high-value constraints matched to OfficeQA’s actual failure modes outperformed adding more rules:
exact metric-name matching (e.g., “outstanding” requires the outstanding column, not “sales and redemptions”)
correct fiscal-year handling (pre-1977 = July–June; transition quarter; post-1976 = October–September)
anchoring to the right table family before extraction (match caption + metric phrase, not just date labels)
preferring explicit totals over reconstructed sums
using bracket-safe sequence output for list-valued answers
The strongest submission was a simple goose-based bundle. Simpler prompt bundles consistently generalized better than larger ones.
How the work proceeded
The workflow was trace-driven rather than score-driven.
Initial debugging used 5-task local runs and classified failures into categories: no-answer stalls (F1), script crashes (F2), wrong data extraction (F3), wrong computation (F4), wrong file retrieval (F5), timeouts (F6), bash syntax errors (F7), permission denied (F8), and output format mismatches (F9).
Prompts, skill contracts, and the failure-mode checklist were edited in small steps, then targeted tasks were rerun to verify whether a specific failure mode actually moved.
Local models provided debugging signal; leaderboard submissions were the real evaluation (OfficeQA scored server-side with MiniMax M2.5).
EvoSkill’s
proposemode generated candidate prompt/skill edits from traces;distillsummarized passes and failures into reusable patterns (fiscal_year,sequence_output,debt_table,quoted_metric, etc.).The first EvoSkill-guided submission (
f0b74a08, opencode, 143.655) scored below baseline, but the workflow separated repeatable patterns from isolated failures.After goose outperformed opencode, the focus shifted to clean staged goose submissions. EvoSkill shifted to distillation and diagnosis.
Choosing the right harness and maintaining a solid baseline mattered more than expanding prompts.
Leaderboard progression
Score by submission
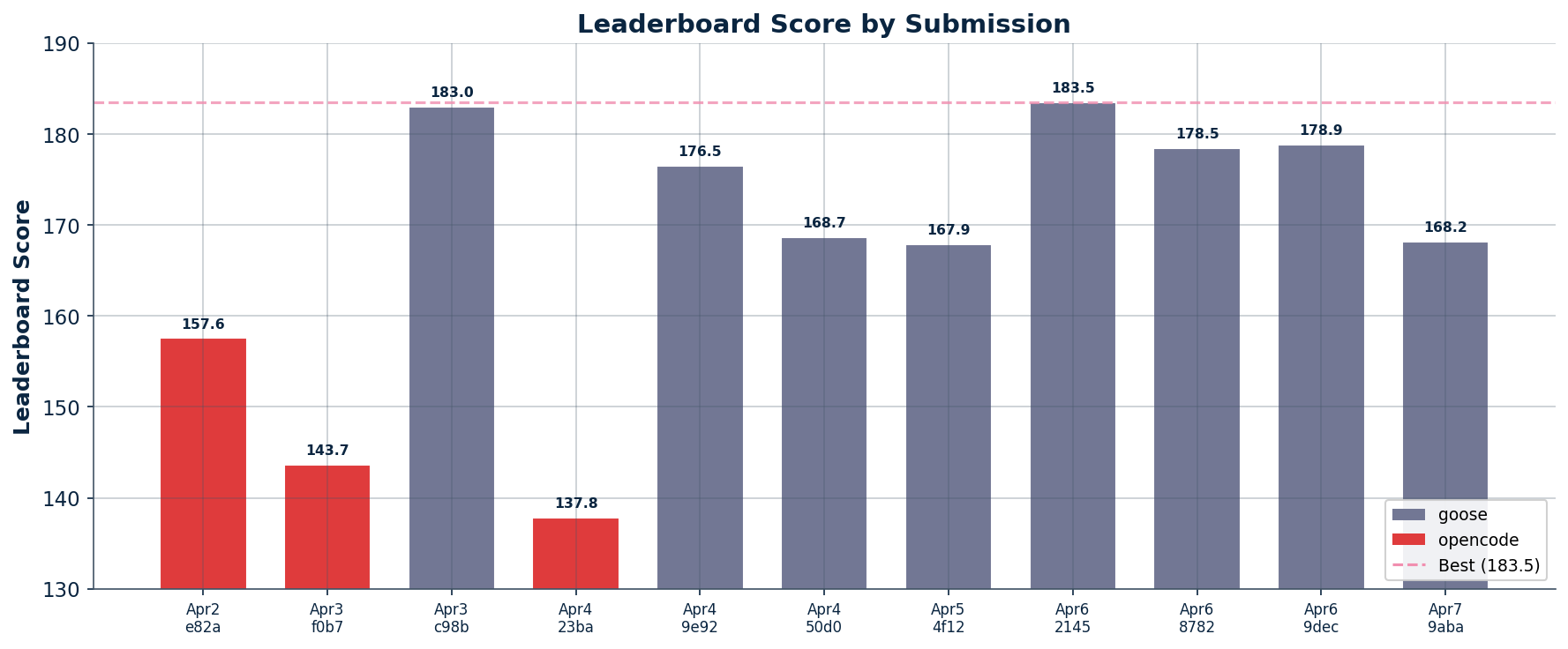
| # | Date | Short ID | Harness | Score | Main change |
|---|---|---|---|---|---|
| 1 | Apr 2 | e82a1479 | opencode | 157.567 | Early opencode baseline |
| 2 | Apr 3 | f0b74a08 | opencode | 143.655 | EvoSkill-guided opencode pass |
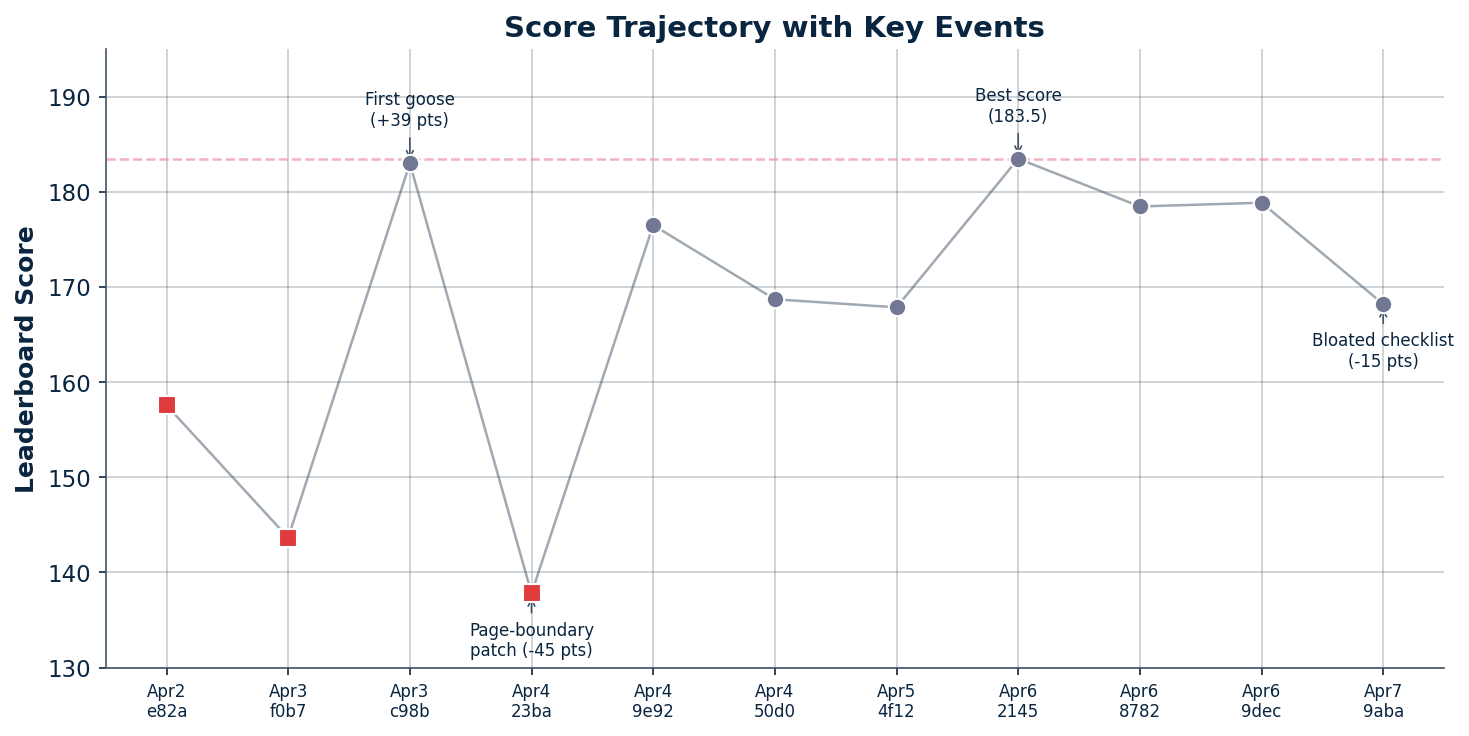
| 3 | Apr 3 | c98b59cc | goose | 182.993 | First goose submission |
| 4 | Apr 4 | 23ba4d7a | opencode | 137.799 | Page-boundary / chart patch |
| 5 | Apr 4 | 9e92c9db | goose | 176.498 | Safe fixes: FY, units, totals |
| 6 | Apr 4 | 50d0bbd4 | goose | 168.706 | HP-filter + debt-table fixes |
| 7 | Apr 5 | 4f1209e8 | goose | 167.863 | Reported-values retrieval rule |
| 8 | Apr 6 | 21458905 | goose | 183.481 | Best simpler goose bundle |
| 9 | Apr 6 | 8782928a | goose | 178.462 | +metric match +CY guard |
| 10 | Apr 6 | 9decca84 | goose | 178.857 | +metric match +softened CY |
| 11 | Apr 7 | 9aba8eca | goose | 168.202 | Metric match + bloated checklist |
| 12 | Apr 7 | dfcbc10d | goose | 166.102 | Exact resubmit of 183.481 bundle |
All leaderboard submissions in chronological order.
Headline numbers
Best score: 183.481 (submission 8 of 12)
Gain over first verified leaderboard baseline: +25.914 (157.567 → 183.481)
Goose mean score across 9 submissions: ${\sim}176$ vs. opencode mean across 3 submissions: ${\sim}146$
First goose submission (182.993) was already within 0.488 of the final best score
Best local 20-task result was 16/20 (80%), but that config scored only 178.462 on the leaderboard
Harness comparison
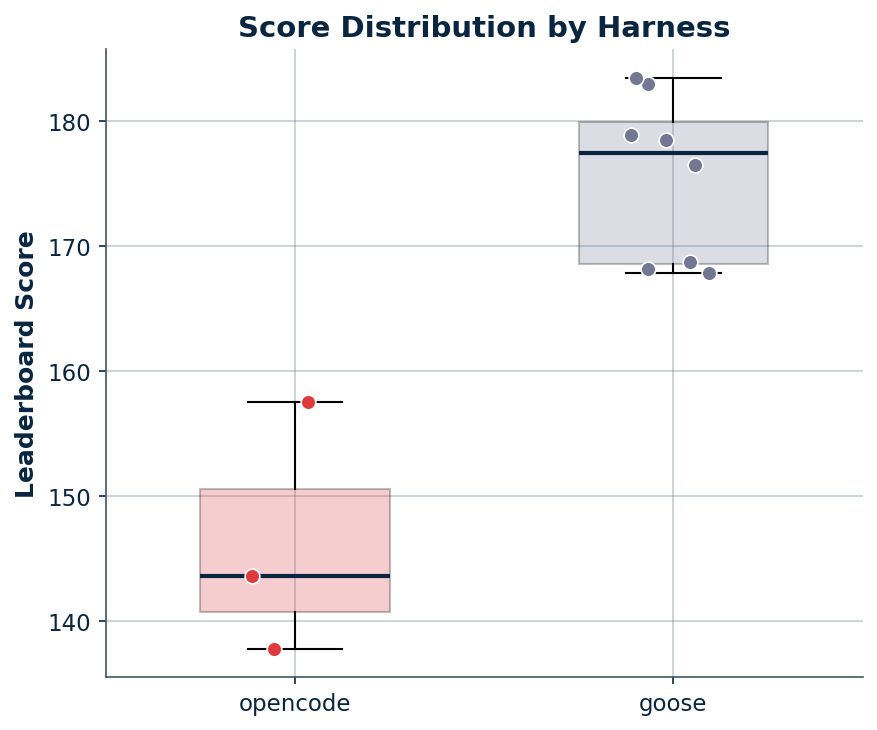
| Harness | Submissions | Mean | Min | Max |
|---|---|---|---|---|
| opencode | 3 | 146.3 | 137.8 | 157.6 |
| goose | 9 | ~175.6 | 167.9 | 183.5 |
Score trajectory with key events
Non-deterministic variance
Submissions with near-identical configs showed ~7-point variance:
| Config family | Scores observed |
|---|---|
| Goose + safe fiscal/unit/total fixes | 176.498, 168.706, 167.863 |
| Goose + simpler bundle | 182.993, 183.481 |
| Goose + metric-match additions | 178.462, 178.857 |
This variance means a 5-point score change between submissions may be noise, not signal.
Local accuracy vs. leaderboard score
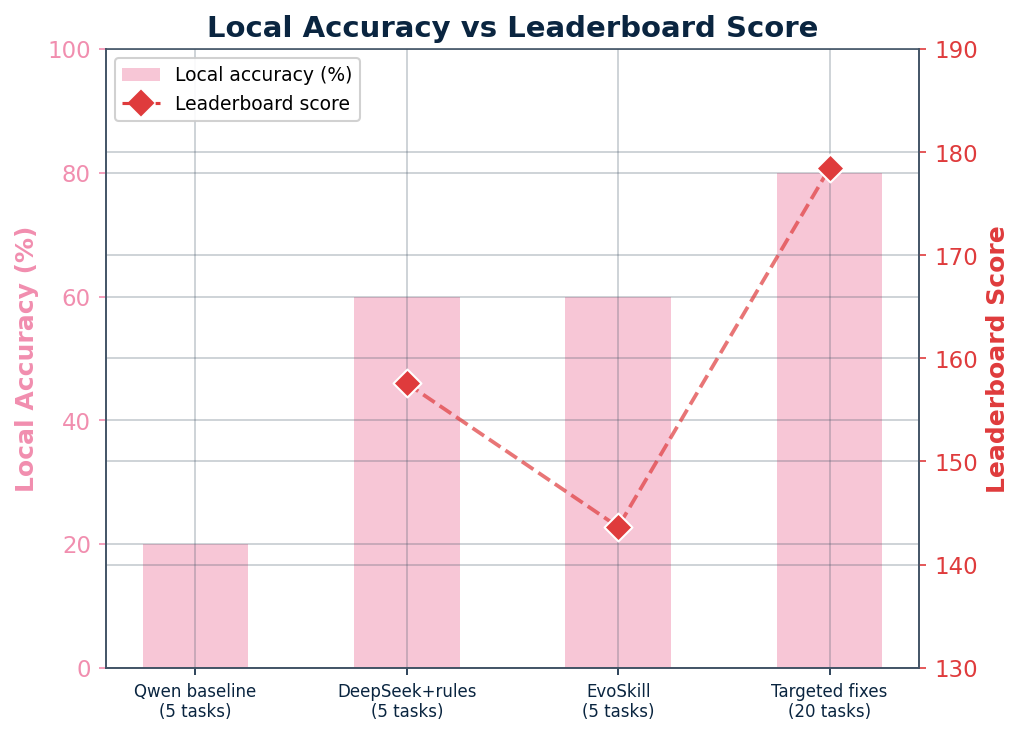
| Local run | Local acc. | Leaderboard | Gap |
|---|---|---|---|
| Qwen baseline (5 tasks) | 20% | — | — |
| DeepSeek + rules (5 tasks) | 60% | 157.567 | — |
| EvoSkill iter (5 tasks) | 60% | 143.655 | Local held, LB fell |
| Targeted fixes (20 tasks) | 80% | 178.462 | Local up, LB fell vs 183.5 |
The 20-task local sample did not represent the full ~246-task hidden pool.
Findings
What helped vs. what hurt
| Change | Effect | Evidence |
|---|---|---|
Switching to goose | Strong + | Jumped to 182.993; goose avg ~176 vs opencode ~146 |
| Keeping prompts shorter | Strong + | Best score from simpler bundle; more rules → 178.x and 168.x |
| Exact metric-name matching | Positive | Fixed uid0012 and uid0227 |
| Fiscal-year / totals / units | Positive | Recovered uid0041, uid0127, uid0220 |
| Table-family anchoring | Positive | Turned uid0057 and uid0111 into local passes |
| EvoSkill distillation | Mixed | First submission regressed; distill loop was high-value for debugging |
| Over-expanding to many files | Negative | Retrospective tables often better than month-by-month |
| Calendar-year guard | Negative | Both variants regressed below 183.481 |
| Page-boundary rules | Negative | Fell to 137.799 — worst score, -45 point regression |
| Large failure-mode checklist | Negative | Inadvertently packaged 104-line checklist → 168.202 |
| Visual chart questions | Unresolved | uid0030 remained unsolved from text-only corpus |
Summary of changes and their observed effects.
OfficeQA patterns
Exact metric identity beats loose topic matching. “Outstanding” vs “sales,” “gross interest” vs “net interest,” and quoted metric names were common failure points.
Treasury time semantics matter. Pre-1977 fiscal years, the 1976 transition quarter, and publication-lag effects are all relevant, but over-applying calendar-year logic hurts.
Fewer files can be better. One retrospective summary table often beat expanding to 12 monthly bulletins.
List outputs are format-sensitive. Sequence-valued answers required bracketed syntax (
[v1, v2, v3]) even when the question said “comma-separated.”Complex prompt bundles were penalized. Targeted, high-confidence fixes outperformed generic rule accumulation.
EvoSkill helped organize, not auto-optimize. The distillation loop that turned traces into skill tags was more useful than the proposal generator.
Visible task performance across submissions
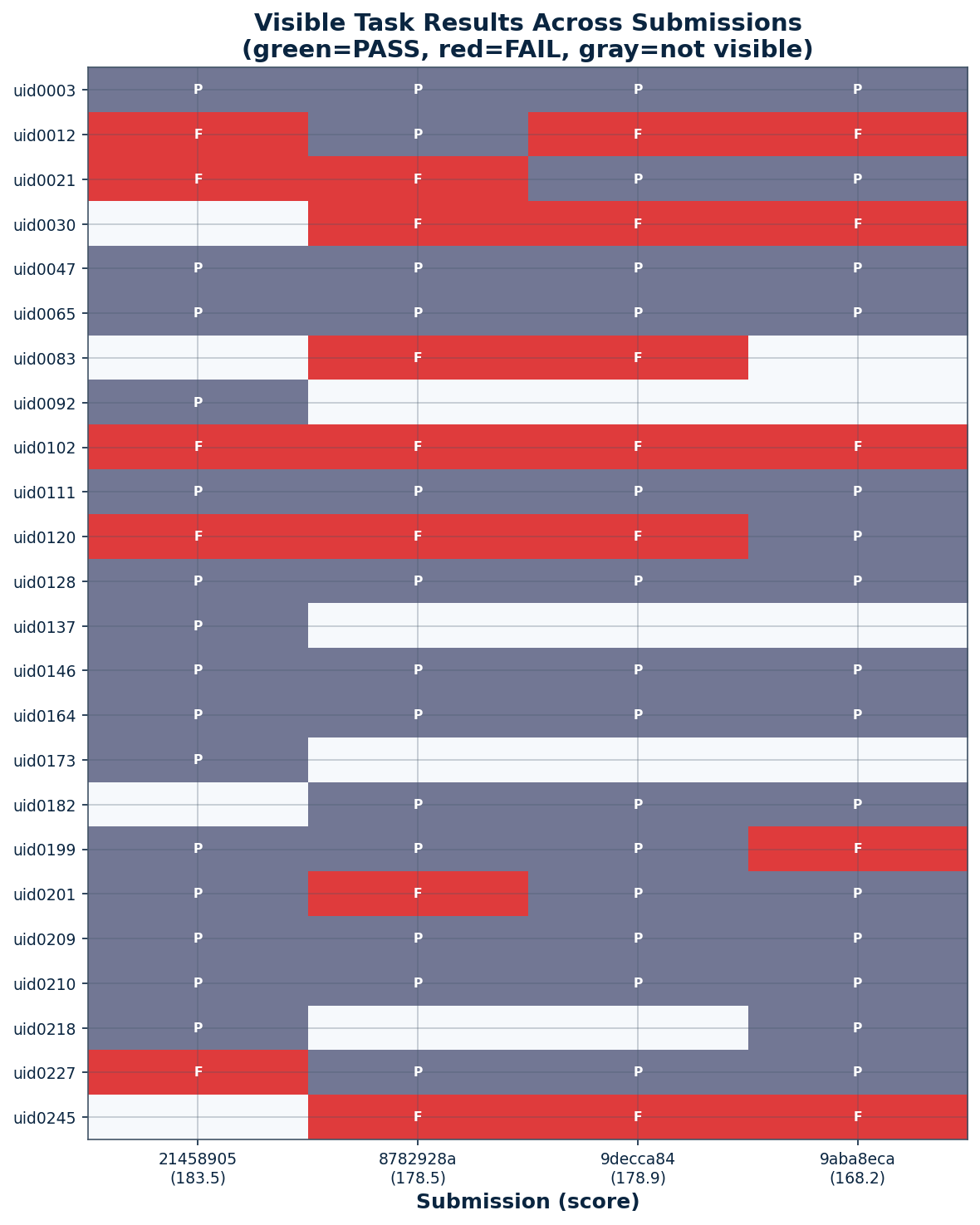
Always passed (across all goose submissions where visible): uid0003, uid0047, uid0065, uid0128, uid0146, uid0164, uid0209, uid0210, uid0111.
Always failed: uid0030 (visual chart), uid0102 (timeout/computation), uid0245 (unknown).
Flipped by specific fixes:
uid0012: FAIL → PASS after metric-name matching rule (submission 9)
uid0227: FAIL → PASS after metric-name matching rule (submissions 9–11)
uid0021: FAIL → PASS intermittently (passed in submissions 10, 11)
uid0199: usually PASS, regressed to FAIL when checklist file was bloated (submission 11)
What EvoSkill specifically contributed
| Component | What it did for us | Net value |
|---|---|---|
propose loop | Suggested candidate edits after failures | Useful for breadth; needed manual filtering |
distill loop | Mined passes and failures into abstract skill tags | High value; made debugging faster |
| Trace-to-skill workflow | Classified misses as retrieval, parsing, arithmetic, or formatting | High value; reduced random tinkering |
| Direct leaderboard lift | Limited | First EvoSkill submission was worse than baseline |
EvoSkill component contributions.
Feedback for Arena
| Issue | Impact | Suggestion |
|---|---|---|
| Trace access was partial | Missing per-task trajectories blocked deeper debugging | Make trajectories consistently downloadable |
| Local vs leaderboard opacity | Changes looked strong locally but regressed on hidden pool | Clarify differences between local and leaderboard execution |
| Harness logging inconsistency | Some runs logged as goose when config said opencode | Make resolved harness explicit in artifacts |
| Infra failures vs prompt failures | API key issues, rate limits, and stalled containers created noisy signals | Surface config/env failures more clearly |
| Memory override warnings | Unclear whether warning affected leaderboard eligibility | Clarify origin and scope of the warning |
Feedback for Arena organizers.
Bottom line
Key takeaways: (1) use the goose harness; (2) match metrics precisely to the question’s wording; (3) get fiscal-year and table context right; (4) enforce output formatting strictly. Extra rules reduced effectiveness.
Given another submission round, the 183.481 bundle would stay unchanged. Remaining budget would go toward resubmitting the same config to counter the ~7-point variance. A simple baseline maintained carefully beats continued elaboration.