Living document. Code and data will be open-sourced.
Introduction
Large language models (LLMs) show surprising competence at multi-step reasoning when guided by chain-of-thought (CoT) prompting. Standard examples are reproduced below from Wei et al.1:
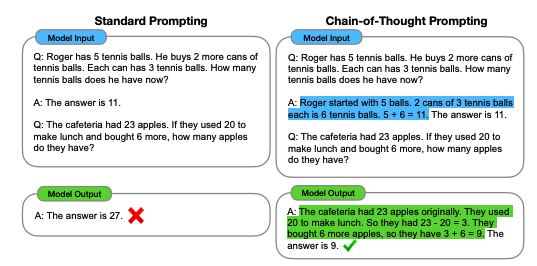
What computational mechanism enables this scaffolded problem-solving? Human cognition is shaped by biological constraints and embodied experience; LLMs derive their reasoning capability solely from pretraining on next-token prediction. The paradox is worth examining: how do CoT prompts reconfigure a model’s forward passes to emulate structured reasoning?
CoT as latent circuit activation
One hypothesis is that CoT prompting activates pathways already shaped during pretraining, rather than installing new skills. The behavior decomposes into three subroutines:
- Decompose the problem into intermediate variables.
- Propagate state across steps while preserving task-relevant information.
- Synthesize the final answer from accumulated intermediates.
Dutta et al.2 argue that such a mechanism exists in larger models (e.g. LLaMA-7B), described as decision, copy, and induction.
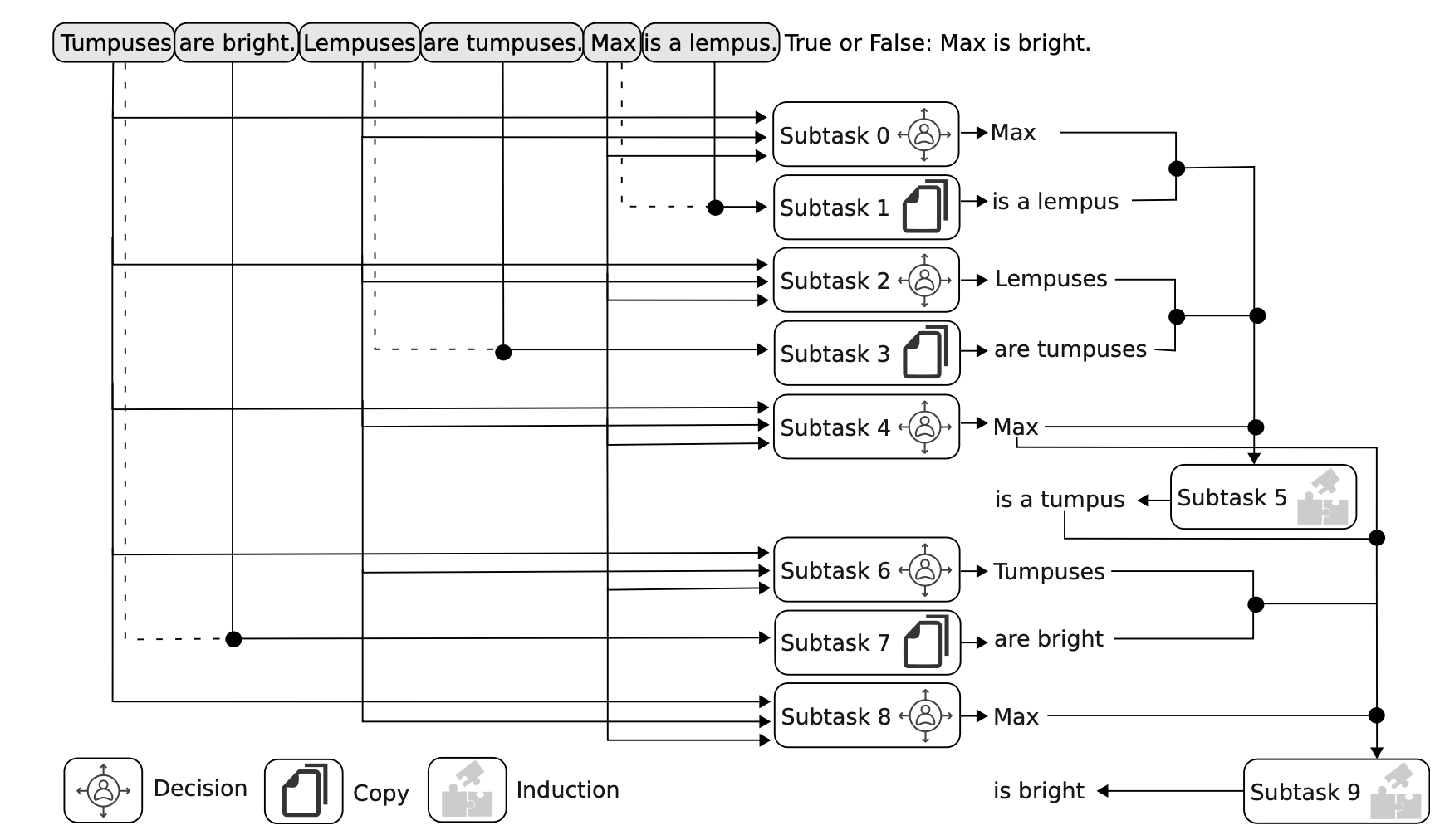
This behavior is consistent with transformer architectures implementing state machines: attention patterns and MLP-mediated computations carry task state from step to step.
A mechanistic lens on reasoning
The remainder of this post walks through a small case study: arithmetic on GPT-2. Mechanistic interpretability research aims to reverse-engineer neural networks into human-understandable components, often expressed as modular circuits. Using the TransformerLens library3, the weights of the model’s attention heads can be extracted and the resulting patterns inspected directly.
Problem: “If 3x + 12 = 30, what is x?”
Input: 3x + 12 = 30. x =
Output: 6
References
Citation
Cited as:
Amanfu, Robert. (Feb 2025). Mechanistic Interpretability of Chain of Thought (CoT) prompting. Robert’s Bytes. https://pubs.onrender.com/posts/mechinterp_cot/.
Or
@article{amanfu2025mechinterp_cot,
title = "Mechanistic Interpretability of Chain of Thought (CoT) prompting",
author = "Amanfu, Robert",
journal = "www.ramanfu.online",
year = "2025",
month = "Feb",
url = "https://pubs.onrender.com/posts/mechinterp_cot/"
}